
Introduction
In spring of 2022, I had to complete a research project for my computer science degree. Due to the nature of my work, gRPC load balancing was front of mind for me, so I picked it as my research topic.
To conduct my research, I set up a Kubernetes cluster on my home network using 5 hand-me-down laptops, wrote some microservices, deployed them, and collected metrics on their load balancing behaviors.
Why is gRPC load balancing interesting? Because gRPC does not load balance in Kubernetes by default. gRPC’s single long-lived connections “breaks” load balancing by bypassing the advantages from the normal Kubernetes load balancing behavior. This article explains why this happens in gRPC Kubernetes microservices but doesn’t in normal Kubernetes microservices, and shows how to workaround this issue to get load balancing in gRPC Kubernetes microservices.
Normal Kubernetes Service Behavior
In a “normal” Kubernetes service, the service is a REST object that abstracts the clients from the need to keep track of the IP addresses of a deployment’s pods, since the pods are ephemeral and replicas of one another. The service offers a single cluster IP address, and the kube-proxy handles load balancing by default.
e.g. From https://github.com/thaigoonch/restgoonch/blob/main/k8s.yaml:
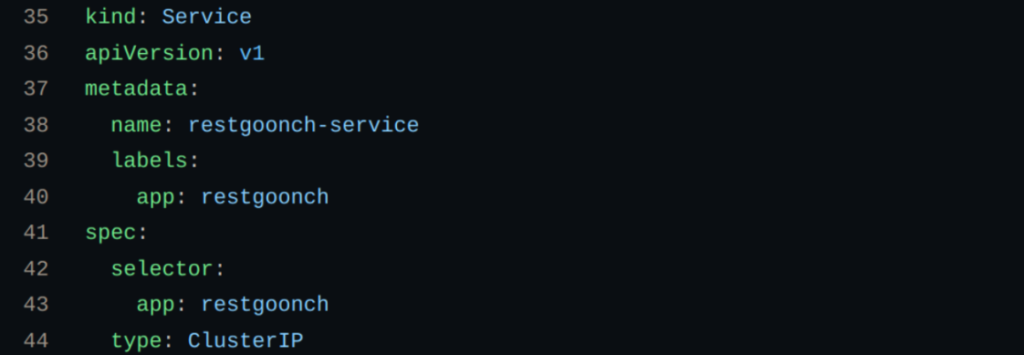
Here is a code snippet of a normal (REST) Kubernetes service of type ClusterIP, which means the service is available within this cluster and only this the cluster. Pay special attention to the ClusterIP part, especially the fact that Kubernetes services use a single cluster IP to advertise the service within the cluster, even though the service may be comprised of multiple pods that each have their own IP’s that are getting cloaked by the cluster IP. That piece is key to understanding the benefits of headless services within the context of gRPC.
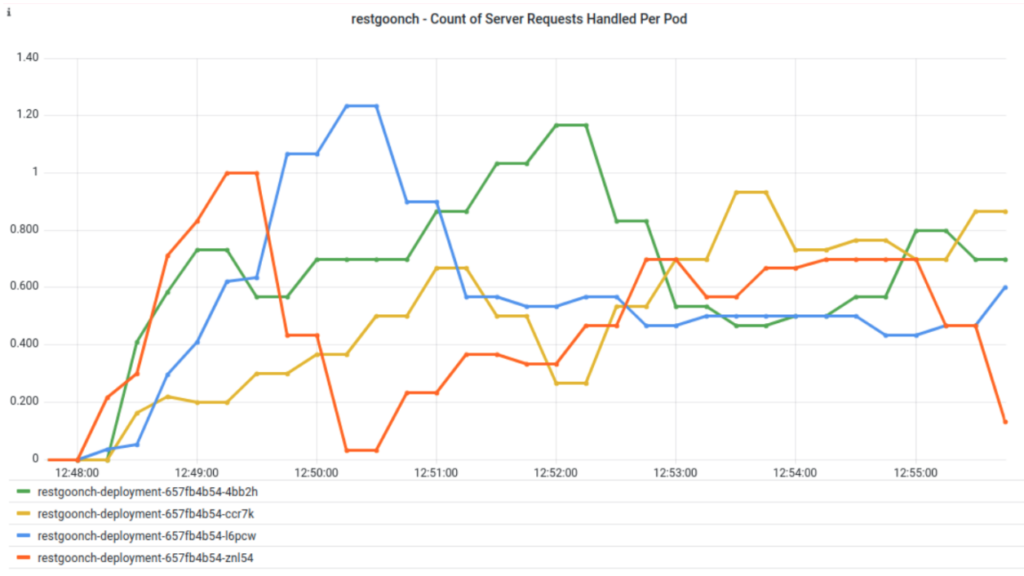
The above graph shows the default load balancing done by the kube-proxy. It displays the rate of REST calls being handled across the four pods in a regular Kubernetes service. This was created by making a REST version of my gRPC microservice and client. It’s doing some load balancing across all four pods.
What is happening behind the scenes to cause this?
The IP address for a Service is allocated by the control plane in the controller manager and stored in the database — etcd.
That same IP address is then used by another component: kube-proxy.
Kube-proxy reads the list of IP addresses for all Services and writes a collection of iptables rules in every node.
Source: https://learnk8s.io/kubernetes-long-lived-connections
For the sake of example, let’s say you have 3 available service pods. This is what the kube-proxy specifies should be done load balancing wise:
If you have three Pods, kube-proxy writes the following rules:
1. select Pod 1 as the destination with a likelihood of 33%. Otherwise, move to the next rule
2. choose Pod 2 as the destination with a probability of 50%. Otherwise, move to the following rule
3. select Pod 3 as the destination (no probability)
The compound probability is that Pod 1, Pod 2 and Pod 3 have all have a one-third chance (33%) to be selected.
Source: https://learnk8s.io/kubernetes-long-lived-connections
gRPC Kubernetes Services
Unfortunately, gRPC Services do not end up being load balanced in Kubernetes due to the nature of gRPC’s single, long-lived connections. And that looks like this:
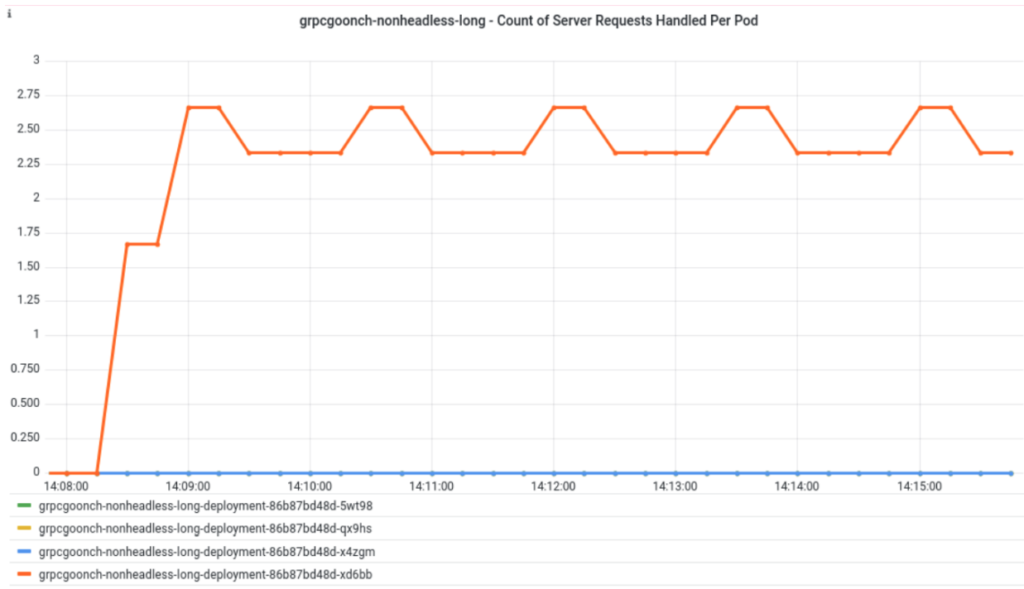
This graph shows the rate of gRPC calls being handled across the four pods in a gRPC service. As you can see, only one server pod is actually utilized despite there being 4 available. This service ran for 8 minutes, and I set the MaxConnectionAge to 8 minutes. Next, let’s learn about what MaxConnectionAge is.
MaxConnectionAge
A MaxConnectionAge can be configured in the gRPC server. The MaxConnectionAge forces the server to close its connection to the client and reconnect to the client after the specified MaxConnectionAge has elapsed. If MaxConnectionAge is not set, it defaults to infinity. This means that, for example, if a client is in the process of sending requests to the server, and you scale the server to have more pods, then the client could potentially use one of them
upon the reconnect.
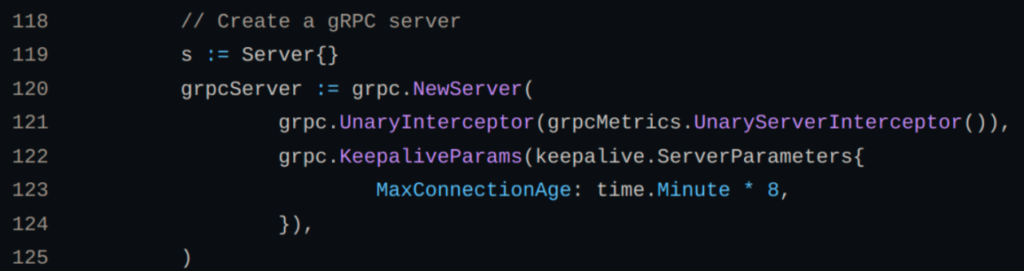
This is part of the gRPC server code in a non-headless gRPC service. The MaxConnectionAge is 8 minutes, and the client in the previous graph ran for 8 minutes as well. I did that to demonstrate that because the server and client never got a chance to reconnect, a gRPC client will just use one pod at a time, no matter how many server pods you have available. This also means if you scale your gRPC service to have more pods, it’s not going to make a difference. The server can only allow for one pod per connection by default with non-headless services in gRPC.
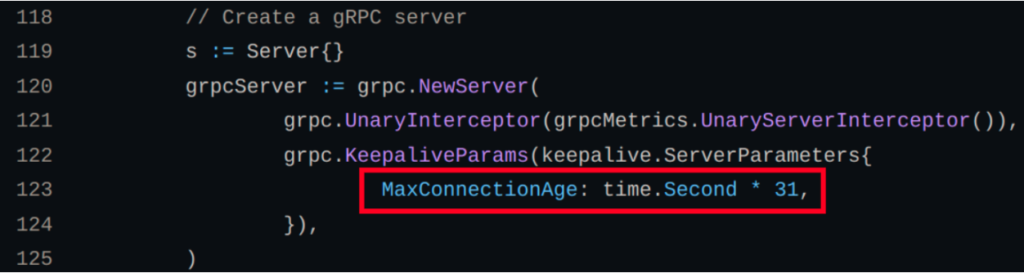
What happens if you reconfigure the server to have a shorter MaxConnectionAge? Well, this means the one-pod-per-connection arrangement is not going to punish a single pod for as long. Below, I’ve shortened the MaxConnectionAge from 8 minutes to 31 seconds.
The below graph shows the rate of gRPC calls being handled by the four pods in a non-headless service with a 31 second MaxConnectionAge:
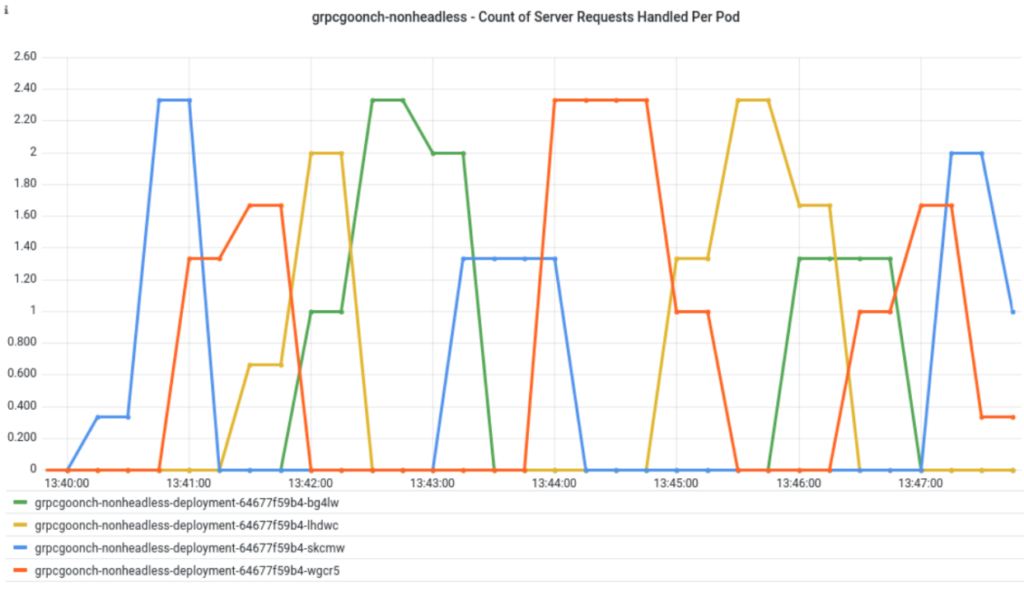
If your MaxConnectionAge is shorter than it takes to do the work of the current requests, you will get some nice overlapping in which multiple server pods are doing work at the same time. Basically, a shorter MaxConnectionAge can be used to force the client to bounce between available server pods, somewhat, and with limited load balancing benefit. But how can we get some better load balancing with our gRPC microservices?
How to Accomplish Load Balancing in gRPC Kubernetes Services
The best known way to improve load balancing is to enforce load balancing within the client. However, for a client to manage load balancing requests, it does need to be aware of all the service’s available pod IP’s. Since a regular Kubernetes service abstracts the client away from the individual pod IP’s, that feature must be bypassed for the client to balance requests among the available server pods. This is possible by making the service a headless service.
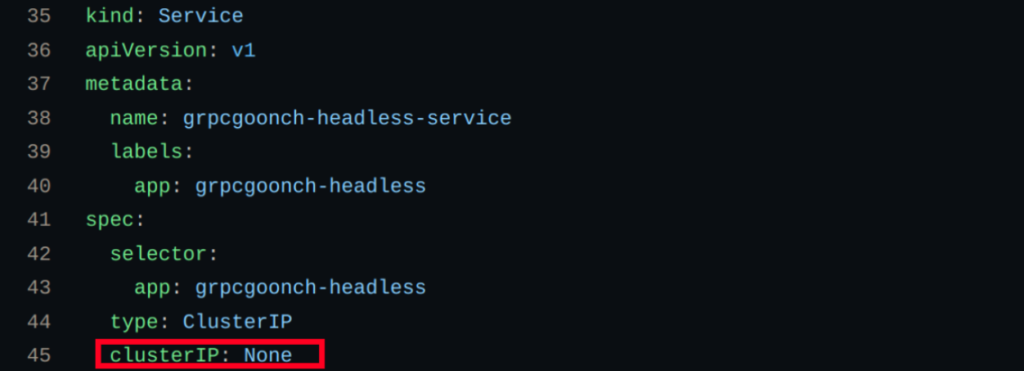
A headless service can be implemented simply by setting the “ClusterIP” in the service to “None” in the Kubernetes configuration. Doing so excludes the service from advertising a single cluster IP, thus making the Service “headless”. Recall the yaml snippet for the normal REST Kubernetes service above. The headless service yaml snippet below is virtually identical, with that single key difference.
From https://github.com/thaigoonch/grpcgoonch-headless/blob/main/k8s.yaml:
After deploying the headless service, you can actually see that the pod IP’s are no longer being abstracted away in an nslookup while exec’d into the pods:
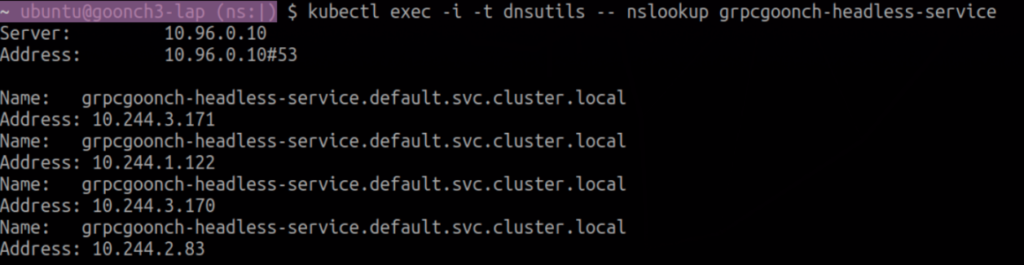
Above is an nslookup result displaying four IP addresses, one for each pod, advertised for a headless Service. The client is able to see all of them.
For comparison, below is an nslookup result displaying the single IP address used to represent the service as a whole in a non-headless (regular) service:

gRPC’s Default “Load Balancing” Behavior
The default “load-balancing” behavior of gRPC Kubernetes microservices is called “pick first”, and it is not really load balancing at all. Pick first is what gRPC Services do by default unless otherwise configured. The logic is as follows:
- The client gets a list of the server pods’ IP addresses
- The client attempts to connect to them
- The first address that the client can successfully connects to is chosen
- All gRPC calls are sent to that address, until it disconnects, which starts the process over again
Below is an example of a gRPC client with pick first implemented.

On line 44, I am specifying pick first as the desired load balancing option. Line 44 is technically unneeded in this case, since pick_first is the default, but I’ve included it here so it’s obvious this service uses pick first.
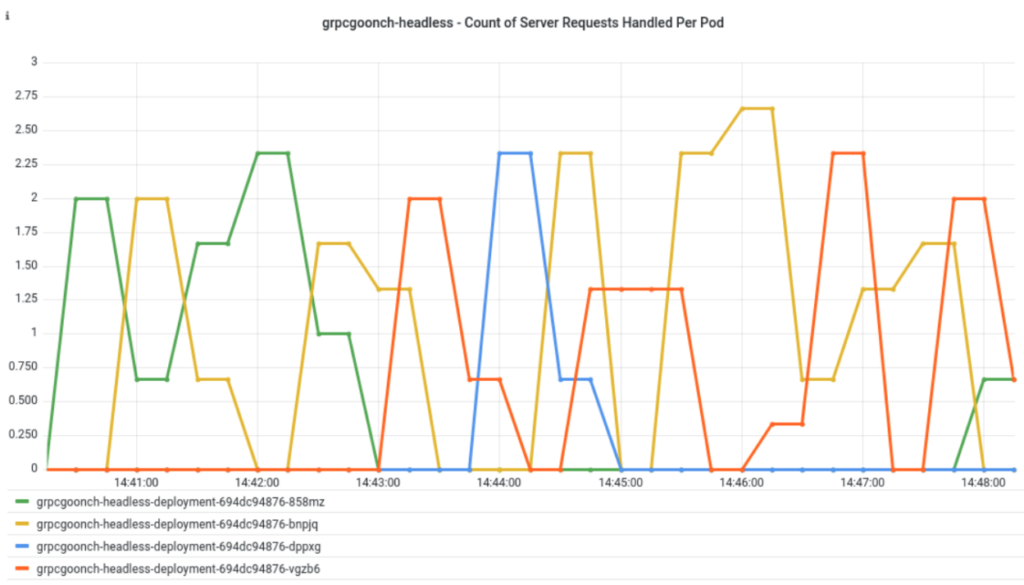
The graph below shows the rate of a “pick first” client’s RPC calls being handled by the four pods in a headless service with an 8 minute MaxConnectionAge.
Once again, only one server pod is actually utilized despite there being 4 available.
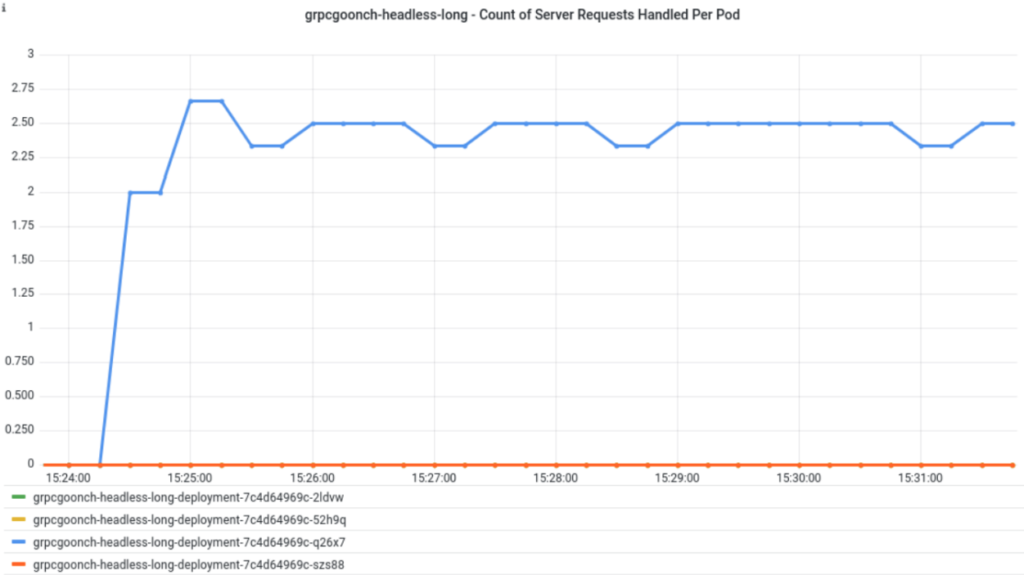
The graph below shows the same thing but with the 31 second MaxConnectionAge:
Again, this is the same behavior we saw earlier when we talked about shortening the MaxConnectionAge. The only difference between these graphs and the ones before is this service is headless. But, we aren’t really seeing any differences in how it behaves.
What have we learned? Using a headless service on the server side and leaving the default “pick first” logic on the client side doesn’t really provide you any load balancing benefit in and of itself. Luckily, Go’s gRPC library has some built-in functionality for load balancing using round robin logic. Let’s look at how that works and can be implemented.
Round Robin Load Balancing
Round robin load balancing means the client iterates through the available server pods in an ordered loop and assigns calls to them accordingly. The logic is as follows:
- The client gets a list of the server pods’ IP addresses
- The client attempts to connect to them
- The client distributes gRPC calls to the successfully connected IP addresses in a round robin fashion
Here’s the pertinent code snippet from a gRPC client.

The required pieces are as follows:
- Line 42: It is connecting to a headless service, which, as we discussed earlier, is required in order for this to work.
- Line 44: It is using the “WithDefaultServiceConfig” option with the “round_robin” “loadBalancingConfig”.
- Line 48: It is using the “dns:///” prefix to the URI path. This is implied in the gRPC documentation. You need to specify the dns URI, and the authority goes in between the “///”, but it gets added by default, so we can just put nothing in there.
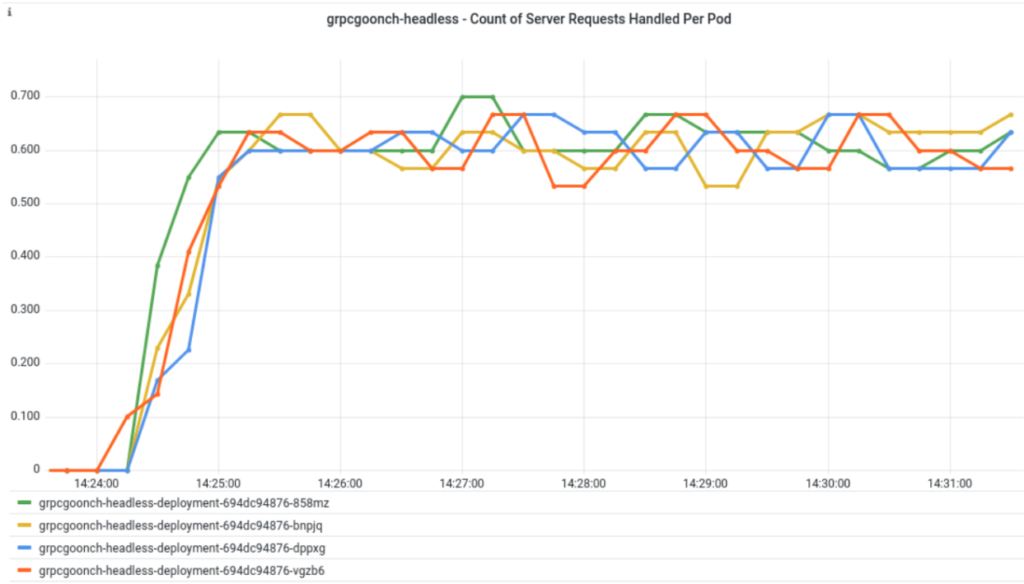
With round robin load balancing implemented client-side, we should expect to see load balancing in action. The below graph shows the rate of a “round robin” client’s RPC calls being handled by the four pods in a headless Service with an 8 minute MaxConnectionAge:
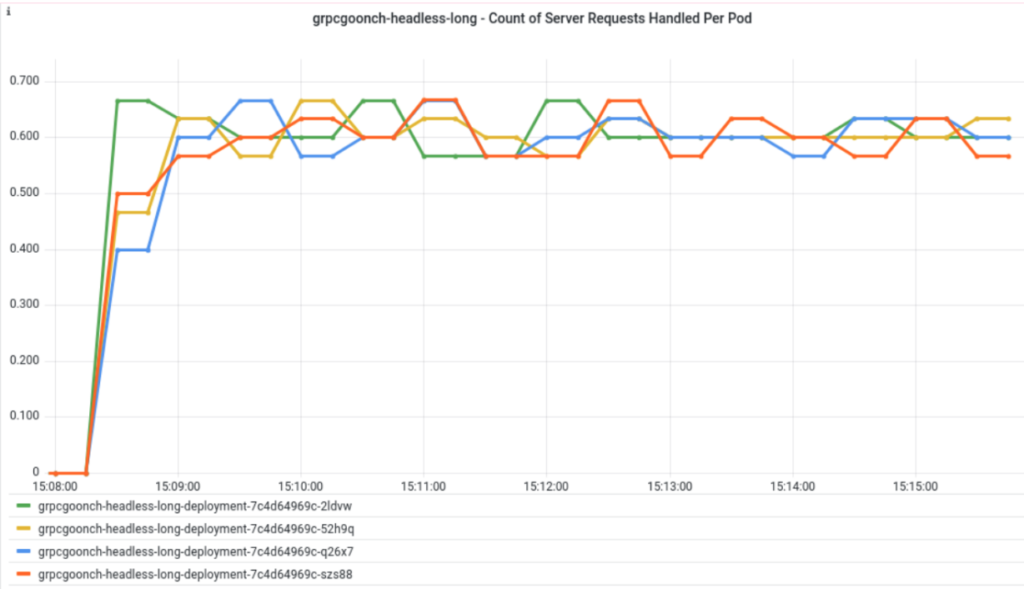
And this graph shows the round robin load balancing with the 31 second MaxConnectionAge:
It really doesn’t look too different from the graph with the 8 minute and 31 second MaxConnectionAge, but scaling situations is where tweaking the MaxConnectionAge can really shine. It can be deduced that this round robin-configured client plus headless service configuration makes it so the server can be scaled. Meaning, creating additional server pods by modifying the replicas in the deployment to a higher number means the workload would actually be distributed across more server pods.
The very exciting graph below shows the results of that:
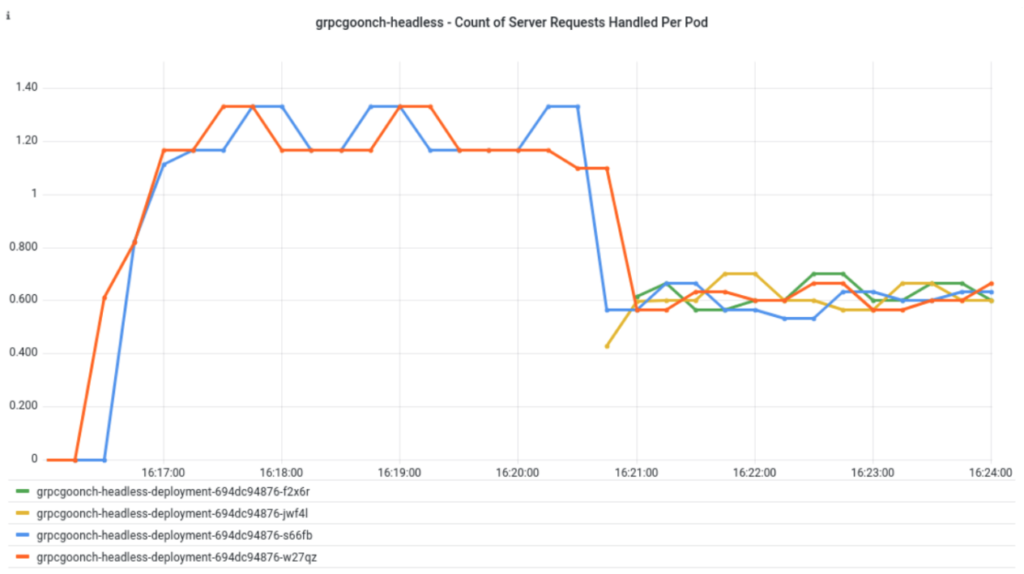
What I did here was initially had the 31 second MaxConnectionAge server deployed, with the replicas set to 2 pods (orange and blue). About 4 minutes in, I scaled the server deployment up to 4 pods. The green and yellow pods joined in about halfway through, taking on equal parts of the server load.
Conclusion
- By default, gRPC locks the client into a single server pod connection for the life of that connection.
- Reducing the MaxConnectionAge on the server can pose as a form of a workaround to distribute some of the load of bulks of client RPC calls.
- Headless services are not required for that, but they are required for enabling true client-side load balancing, such as what I did with gRPC’s Go library’s round robin load balancing option.
- Enforcing round robin load balancing within the client appears to load balance well for both long and short server connection times.
- Doing so also makes it so that scaling the server to create additional server pods will help to handle excess RPC loads, whereas this is not the case by default in Kubernetes for gRPC.